
Researcher / Data Scientist
cminutti@data-fusionlab.com
Biography
I am a researcher in artificial intelligence and data science. I hold a B.Sc. in Statistics from Chapingo Autonomous University, an M.Sc. in Mathematics, and a Ph.D. in Computer Science from the National Autonomous University of Mexico, with a research stay at the University of Waterloo through the Emerging Leaders in the Americas Program.
I am a member of Mexico’s National System of Researchers. My work has received both national and international recognition, including the Mexican Association of Statistics award for the second-best master’s thesis, first place in the Best Paper Award at MICAI 2023, and third place in the AFIRME–UNAM Research Award 2024. I have also received awards in international data science and artificial intelligence competitions, including first place at the International Joint Conference on Neural Networks (IJCNN 2025) and second place at the Iberian Language Evaluation Forum (IberLEF 2025).
I have completed postdoctoral fellowships at both the National Polytechnic Institute and the National Autonomous University of Mexico. I have also worked as a data science consultant and research associate in collaborative AI initiatives.
Selected Publications
Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations: A Multifaceted Analysis
Mathematical and Computational Applications
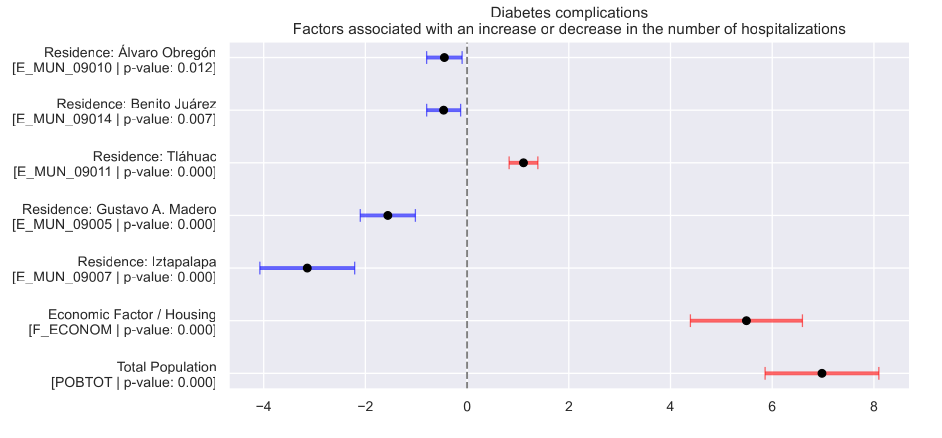
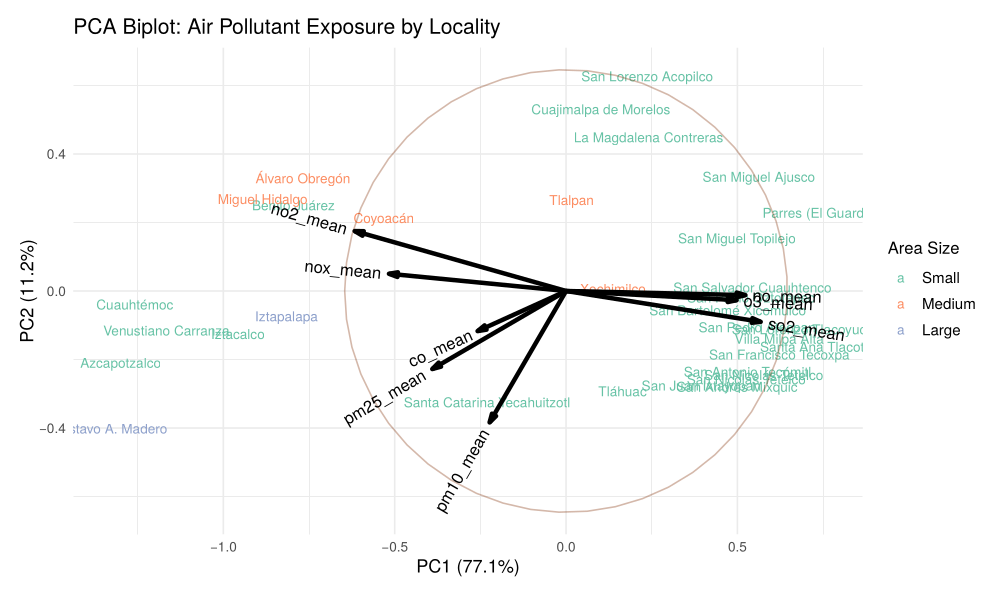
This study investigates the combined effects of air pollution and socioeconomic factors on disease incidence and severity, addressing gaps in prior research that often analyzed these factors separately. Using data from 86,170 hospitalizations in Mexico City (2015–2019), we employed multivariate statistical methods (PCA and factor analysis) to construct composite measures of social and economic status and grouped correlated pollutants. Logistic and negative binomial regression models assessed their associations with hospitalization risk and frequency. Results showed that economic status significantly influenced diabetes complications, while social factors affected prenatal care-related diseases and hypertension. The PM10–PM2.5–CO group increased the incidence of asthma, influenza, and epilepsy, whereas NO2–NOx impacted diabetes complication severity and influenza. Nonlinear effects and interactions (e.g., age and weight) were also identified, highlighting the need for integrated analyses in environmental health research.
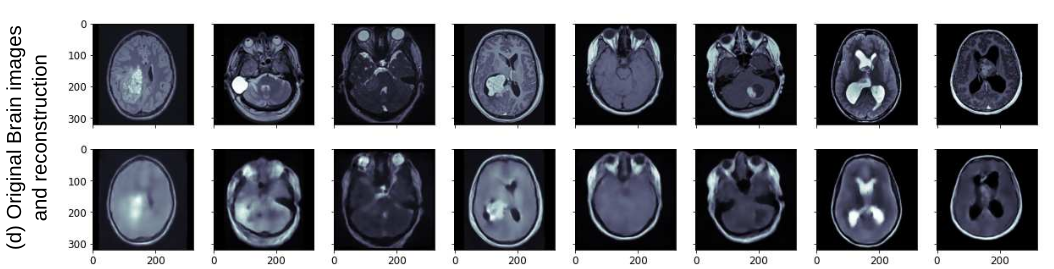
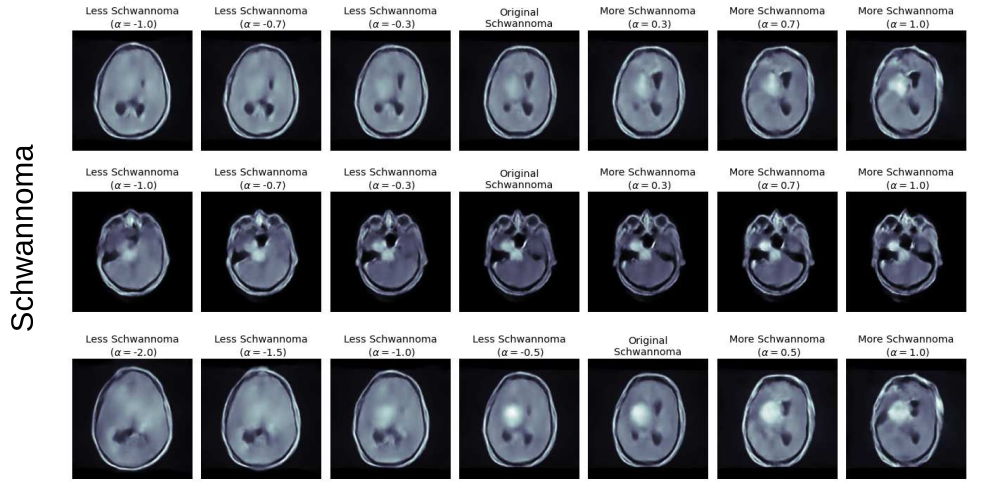
Enhancing interpretability and bias control in deep learning models for medical image analysis using generative AI
Proceedings of SPIE
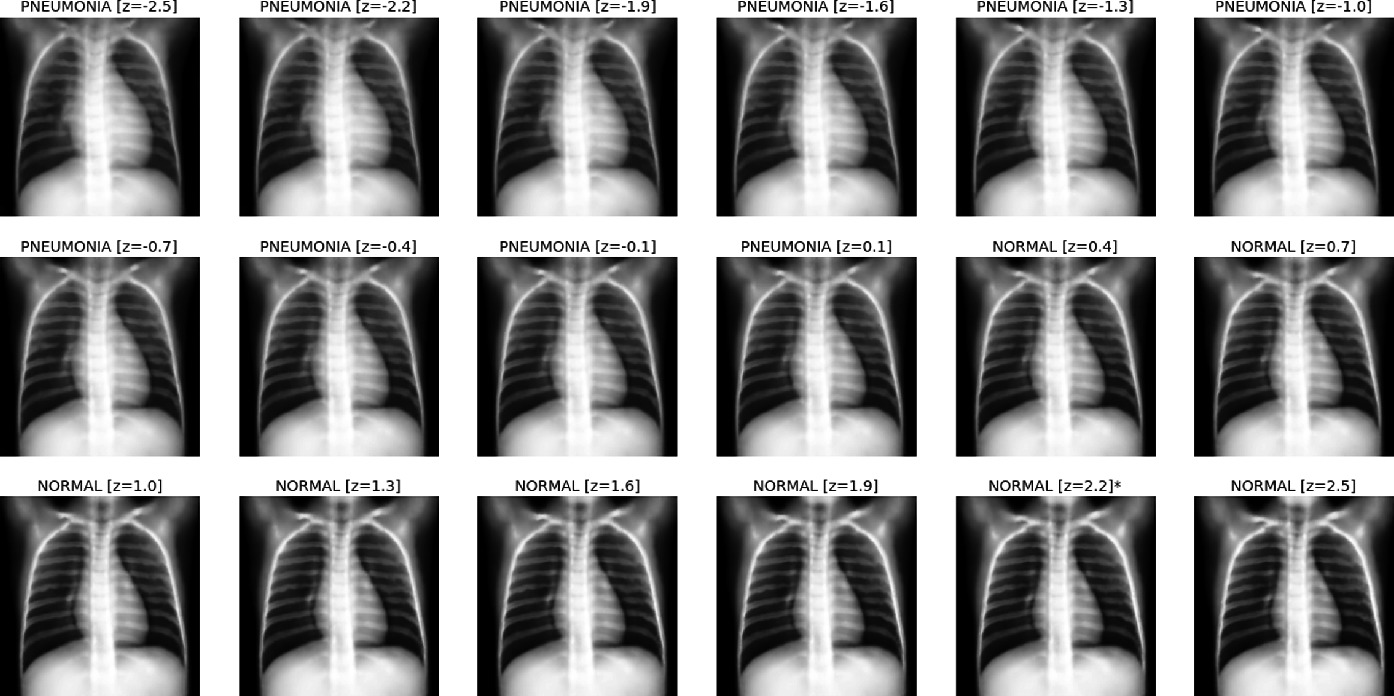
Explainability and bias mitigation are crucial aspects of deep learning (DL) models for medical image analysis. Generative AI, particularly autoencoders, can enhance explainability by analyzing the latent space to identify and control variables that contribute to biases. By manipulating the latent space, biases can be mitigated in the classification layer. Furthermore, the latent space can be visualized to provide a more intuitive understanding of the model's decision-making process. In our work, we demonstrate how the proposed approach enhances the explainability of the decision-making process, surpassing the capabilities of traditional methods like Grad-Cam. Our approach effectively identifies and mitigates biases in a straightforward manner, without necessitating model retraining or dataset modification, showing how Generative AI has the potential to play a pivotal role in addressing explainability and bias mitigation challenges, enhancing the trustworthiness and clinical utility of DL-powered medical image analysis tools.
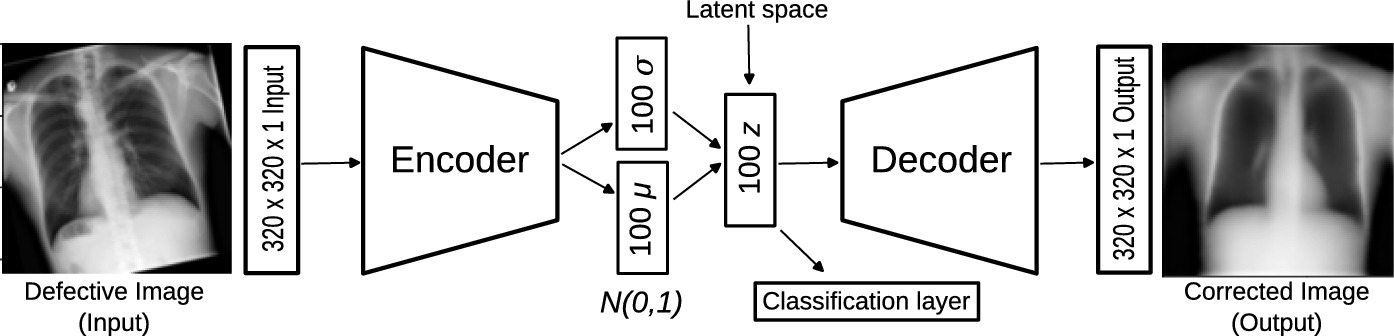
PumaMedNet-CXR: An Explainable Generative Artificial Intelligence for the Analysis and Classification of Chest X-Ray Images
Lecture Notes in Computer Science
In this paper, we introduce PumaMedNet-CXR, a generative AI designed for medical image classification, with a specific emphasis on Chest X-ray (CXR) images. The model effectively corrects common defects in CXR images, offers improved explainability, enabling a deeper understanding of its decision-making process. By analyzing its latent space, we can identify and mitigate biases, ensuring a more reliable and transparent model. Notably, PumaMedNet-CXR achieves comparable performance to larger pre-trained models through transfer learning, making it a promising tool for medical image analysis. The model's highly efficient autoencoder-based architecture, along with its explainability and bias mitigation capabilities, contribute to its significant potential in advancing medical image understanding and analysis.
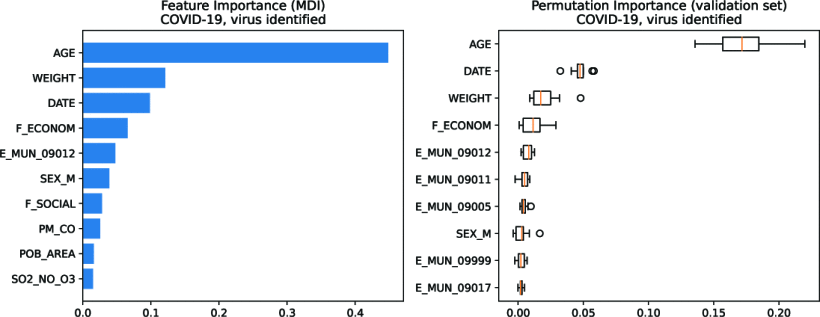
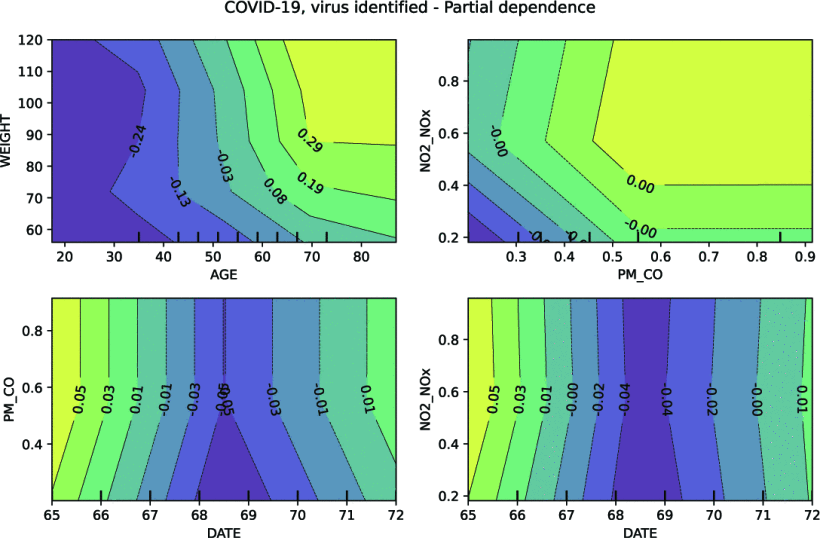
Exploring nonlinear effects of air pollution on hospital admissions by disease using gradient boosting machines
IEEE
Air pollution has been linked to premature mortality and reduced life expectancy, with acute and chronic effects on human health. These effects can be difficult to measure because of possible interactions and nonlinear relationships with other variables such as age, weight, sex, and socioeconomic status. Multi-dimensional relationships are difficult to model using conventional statistical methods. However, modern machine learning techniques have been quite successful in this domain. In this study, gradient boosting regression trees are used to predict the severity/mortality of the leading causes of hospitalization in Mexico City for 91,964 patients during the years 2015–2020 to measure the impact due to different air pollutants. The results show multiple nonlinear relationships and a significant effect of air pollutants on some of the most prevalent diseases.
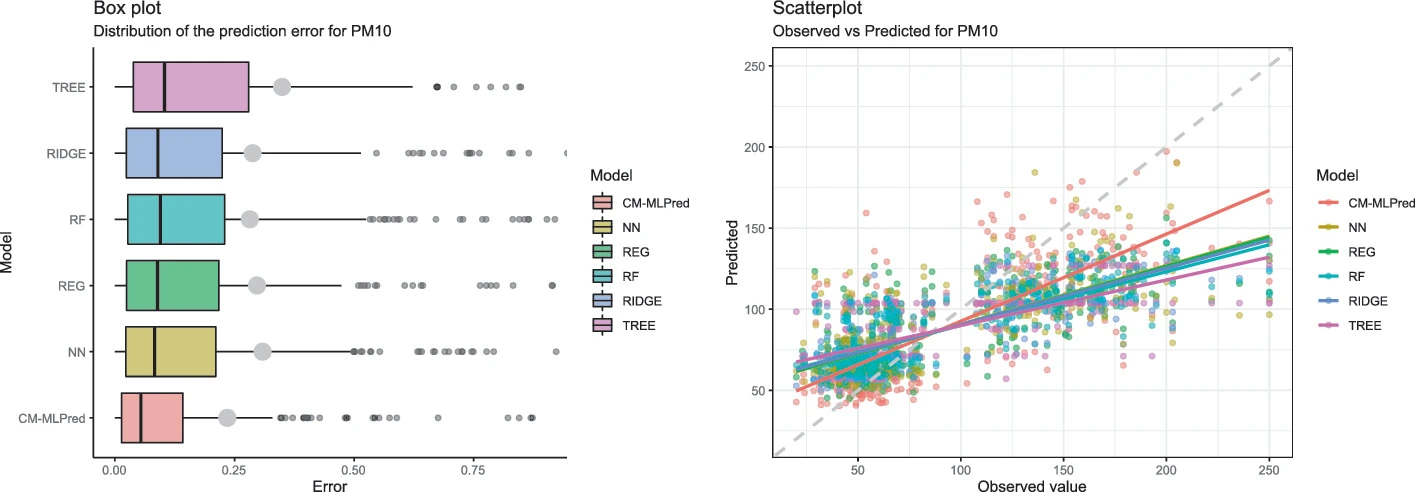
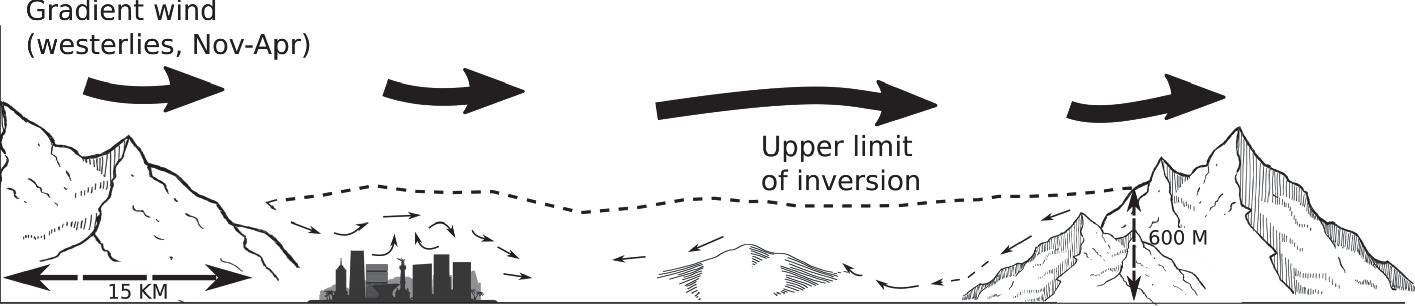
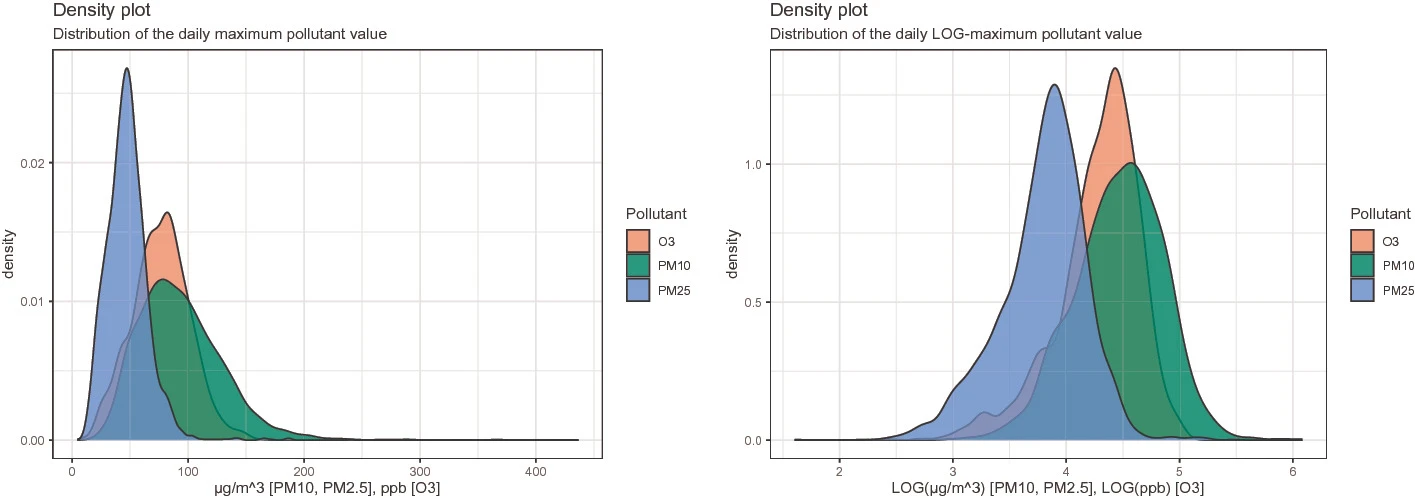
A Hybrid Model for the Prediction of Air Pollutants Concentration, Based on Statistical and Machine Learning Techniques
Lecture Notes in Computer Science
In large cities, the health of the inhabitants and the concentrations of particles smaller than 10 and 2.5 μm as well as ozone are related, making their prediction useful for the government and citizens. Mexico City has an air quality forecast system, which presents a forecast by pollutant at hourly and geographic zone level, but is only valid for the next 24 h.
To generate predictions for a longer time period, sophisticated methods need to be used, but highly automated techniques, such as deep learning, require a large amount of data, which are not available for this problem. Therefore, a set of predictor variables is created to feed and test different Machine Learning (ML) methods, and determine which features of these methods are essential for the prediction of different pollutant concentrations, to develop a hybrid ad-hoc model that includes ML features, but allowing a level of explainability, unlike what would occur with methods such as neural networks.
In this work we present a hybrid prediction model using different statistical methods and ML techniques, which allow estimating the concentration of the three main pollutants in the air of Mexico City two weeks ahead. The results of the different models are presented and compared, with the hybrid model being the one that best predicts the extreme cases.
Publications
-
"Forecasting an Emerging Market Stock Index: a Comparative Study of Classical and Deep Learning Models". Lorenzo-Landa, G., Minutti-Martinez, C..
International Conference in Software Engineering Research and Innovation, (2025). doi: 10.1109/CONISOFT66928.2025.00049. -
"Multitask Analysis of Spanish Travel Reviews: Sentiment, Destination, and Topic Classification with RoBERTa and LLaMA Ensembles". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
CEUR Workshop Proceedings, (2025). -
"Cyclo-VGAE: Dual-Mechanism Approach to GNN Robustness Against Noisy Labels". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
International Joint Conference on Neural Networks (IJCNN), Rome, Italy, IEEE, pp. 1-8, (2025). doi: 10.1109/IJCNN64981.2025.11227407. -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations: A Multifaceted Analysis". Minutti-Martinez, C., Mata-Rivera, M. F., Arellano-Vazquez, M., Escalante-Ramírez, B., & Olveres, J.
Mathematical and Computational Applications, 30(4), 69. (2025). doi:10.3390/mca30040069 -
"Dynamic Wind Condition Detection in Baja California, Mexico: A Machine Learning Approach for Improved Wind Management". Arellano-Vazquez, M., Zamora-Machado, M., Robles Pérez, M., Minutti-Martinez, C., Jaramillo Salgado, M. O.
IEEE Latin America Transactions., 23(5), 387–396. (2025). -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations in Mexico City: A Multifaceted Analysis". Minutti-Martinez, C., Mata-Rivera, M., Arellano-Vazquez, M., Escalante-Ramírez, B., Olveres, J.
Lecture Notes in Computer Science. Springer, Cham. (2025). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population". Minutti, C.
International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). (2024). -
"A comprehensive methodology for performing Continued Process Verification". Carrillo, R., Minutti, C., Lagunes, P.
IEEE 37th International Symposium on Computer-Based Medical Systems. (2024). -
"Enhancing interpretability and bias control in deep learning models for medical image analysis using generative AI". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
Proceedings of SPIE. (2024). -
"PumaMedNet-CXR: An Explainable Generative Artificial Intelligence for the Analysis and Classification of Chest X-Ray Images". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
Lecture Notes in Computer Science. (2023). -
"Exploring nonlinear effects of air pollution on hospital admissions by disease using gradient boosting machines". Minutti-Martinez, C., Galindo, A., Valdez-Garduño, L. F., Mata-Rivera, M. F.
19th International Conference on Electrical Engineering, Computing Science and Automatic Control. IEEE. (2022). -
"A Hybrid Model for the Prediction of Air Pollutants Concentration, Based on Statistical and Machine Learning Techniques". Minutti-Martinez, C., Arellano-Vázquez, M., Zamora-Machado, M.
Lecture Notes in Computer Science. (2021). -
"A New Inverse Modeling Approach for Hydraulic Conductivity Estimation Based on Gaussian Mixtures". Minutti, C., Illman, W. A., Gomez, S.
Water Resources Research. (2020). -
"Automated characterization and prediction of wind conditions using gaussian mixtures". Arellano-Vázquez, M., Minutti-Martinez, C., Zamora-Machado, M.
Lecture Notes in Computer Science. (2020). -
"An algorithm for hydraulic tomography based on a mixture model". Minutti, C., Illman, W. A., Gomez, S.
Lecture Notes in Computer Science. (2019). -
"A machine-learning approach for noise reduction in parameter estimation inverse problems, applied to characterization of oil reservoirs". Minutti, C., Gomez, S., Ramos, G.
Journal of Physics: Conference Series. 1047 (1), 012010. (2018). -
"A stable computation of log-derivatives from noisy drawdown data". Ramos, G., Carrera, J., Gómez, S., Minutti, C., Camacho, R.
Water Resources Research 53 (9), 7904-7916. (2017). -
"Robust Characterization of Naturally Fractured Carbonate Reservoirs Through Sensitivity Analysis and Noise Propagation Reduction". Minutti, C., Ramos, G., Gomez, S., Camacho, R., Vázquez, M., Castillo, N.
SPE Latin America and Caribbean Heavy and Extra Heavy Oil Conference. (2016). -
"Well-Testing Characterization of Heavy-Oil Naturally Fractured Vuggy Reservoirs". Camacho Velazquez, R., Gomez, S., Vasquez-Cruz, M. A., Fuenleal, N. A., Castillo, T., Ramos, G., Minutti, C., Mesejo, A., Fuentes-Cruz, G.
SPE Heavy and Extra Heavy Oil Conference: Latin America (2014). -
"Avances en la caracterización integral de un yacimiento naturalmente fracturado vugular, el caso Ayatsil-Tekel". Camacho Velázquez, R., Fuenleal Martínez, N., Castillo Rodríguez, T., Gómez Gómez, S., Ramos, G., Minutti Martínez, C., Vásquez Cruz, M., Mesejo, A., Fuentes Cruz, G.
Ingeniería petrolera. 54 (10), 583-601 (2014).
International Conferences
-
"Cyclo-VGAE: Dual-Mechanism Approach to GNN Robustness Against Noisy Labels".
International Joint Conference on Neural Networks 2025. Rome, Italy. (2025). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population".
2024 21st International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Cinvestav, Mexico City. (2024). -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations in Mexico City: A Multifaceted Analysis".
6th Workshop on New Trends in Computational Intelligence and Applications. INAOE, Puebla, Mexico. (2024). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population".
21st International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Mexico City, Mexico. (2024). -
"Enhancing interpretability and bias control in deep learning models for medical image analysis using generative AI".
SPIE Photonics Europe 2024. Strasbourg, France. 7-11 April. (2024). -
"PumaMedNet-CXR: An Explainable Denoising Autoencoder for the Analysis and Classification of Chest X-Ray Images".
22nd Mexican International Conference on Artificial Intelligence, 13-18 November, IIMAS-UNAM (UAEY) - UADY, Mérida, Yucatán, México. (2023). -
"Exploring nonlinear effects of air pollution on hospital admissions by disease using gradient boosting machines".
19th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Mexico City, Mexico. (2022). -
"Automated Prediction of Air Pollutant Concentrations in Mexico City, Using Artificial Intelligence Methods".
20th Mexican International Conference on Artificial Intelligence. 25-30 October, Mexico City, Mexico. (2021). -
"An algorithm to perform hydraulic tomography based on a mixture model".
International Conference on Computational Science. 12-14 June, Faro, Algarve, Portugal. (2019). -
"An approach for noise reduction in inverse problems, applied to well-test data".
9th International Conference on Inverse Problems in Engineering. May 23-26, University of Waterloo, ON, Canada. (2017). -
"A Methodology for the Characterization of Naturally Fractured-Vuggy Carbonate Reservoirs Using Statistical Methods".
Eighth International Conference "Inverse Problems: Modeling and Simulation". May 23-28, Ölüdeniz, Fethiye, Turkey. (2016).
Awards and Distinctions
- Top 10 in the "Accelerating Mexico with Artificial Intelligence" (Acelerando México con Inteligencia Artificial) program by Intel, 2025 edition. (2025).
- 2nd Place in the Natural Language Processing (NLP) competition "Researching Sentiment Evaluation in Text for Mexican Magical Towns" (Rest-Mex 2025) at the Iberian Languages Evaluation Forum (IberLEF) 2025.
- 1st Place in the "Learning with Noisy Graph Labels Competition" at the International Joint Conference on Neural Networks 2025 from The International Neural Network Society (INNS).
- 3rd Place in the research category of the AFIRME-FUNAM award, which promotes and recognizes scientific research in Physical-Mathematical Sciences and Engineering, through the National University of Mexico and AFIRME Financial Group. (2024).
- INFOTEC-HUAWEI AI 1000 Talent Development Program Awardee. Out of 1000 participants, the AI 1000 program rewards the top 100 Huawei HCIA-AI certification results with a 2-week AI training program at Huawei's facilities in Hangzhou, China. (2024).
- 1st Place Best Paper Award at the 22nd Mexican International Conference on Artificial Intelligence by the Mexican Society for Artificial Intelligence. (2023).
- Member of the National System of Researchers (SNI). Interdisciplinary Area. (2023).
- Ranked in the top 3% (Silver medal) of the Data Science / AI competition "Google Smartphone Decimeter Challenge", with 810 teams and 985 competitors from around the world. (2021).
- Scholarship recipient of the Emerging Leaders in the Americas Program for short-term exchange opportunities for study or research, in Canada. (2017).
- Second place for the best master's thesis in statistics. National prize by the Mexican Association of Statistics (AME), The Francisco Aranda-Ordaz Prize. (2016).