
Investigador / Científico de Datos
cminutti@data-fusionlab.com
Biografía
Soy investigador en inteligencia artificial y ciencia de datos. Cuento con una licenciatura en Estadística por la Universidad Autónoma Chapingo, una maestría en Matemáticas y un doctorado en Ciencias de la Computación por la Universidad Nacional Autónoma de México, donde además realicé una estancia de investigación en la Universidad de Waterloo, Canadá, a través del programa Emerging Leaders in the Americas.
Soy miembro del Sistema Nacional de Investigadores. Mi trabajo ha sido reconocido a nivel nacional e internacional, incluyendo el segundo lugar a la mejor tesis de maestría por la Asociación Mexicana de Estadística, el primer lugar en el Best Paper Award de MICAI 2023 y el tercer lugar en el Premio AFIRME–UNAM 2024. También he obtenido premios en competencias internacionales de ciencia de datos e inteligencia artificial, como el primer lugar en la International Joint Conference on Neural Networks (IJCNN 2025) y el segundo lugar en el Iberian Language Evaluation Forum (IberLEF 2025).
He realizado estancias posdoctorales tanto en el Instituto Politécnico Nacional como en la Universidad Nacional Autónoma de México. Asimismo, he trabajado como consultor en ciencia de datos y como asociado de investigación en iniciativas colaborativas de inteligencia artificial.
Publicaciones Destacadas
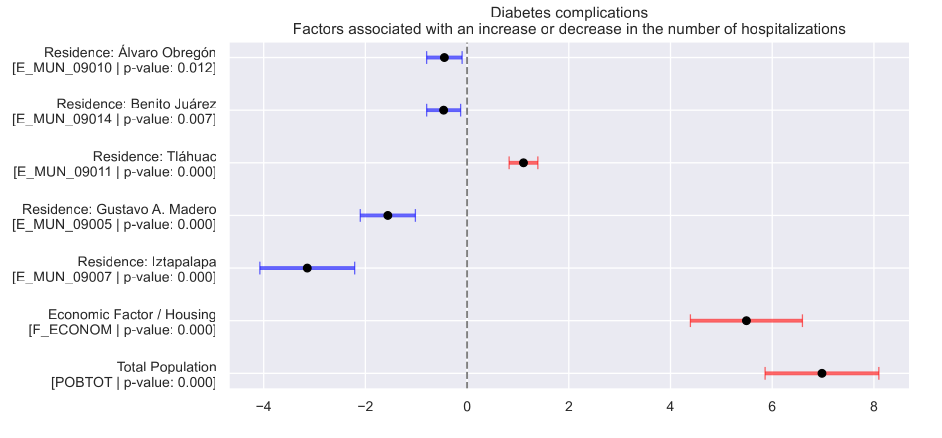
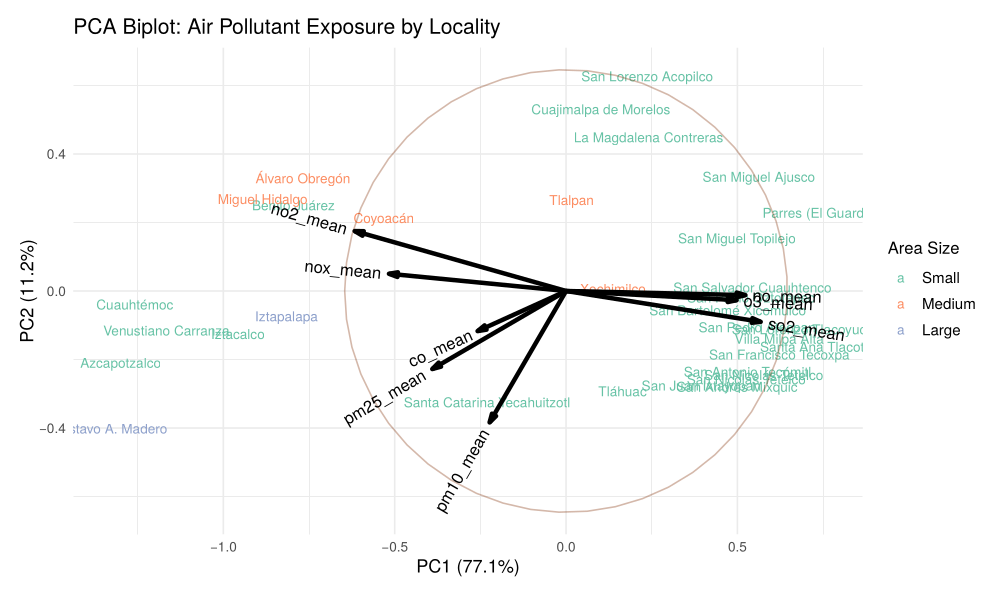
Contaminación del Aire, Estatus Socioeconómico y Hospitalizaciones Evitables: Un Análisis Multifacético
Mathematical and Computational Applications
Este estudio investiga los efectos combinados de la contaminación del aire y los factores socioeconómicos sobre la incidencia y gravedad de enfermedades, abordando vacíos en investigaciones previas que a menudo analizaban estos factores por separado. Utilizando datos de 86,170 hospitalizaciones en la Ciudad de México (2015–2019), empleamos métodos estadísticos multivariados (ACP y análisis factorial) para construir medidas compuestas de estatus social y económico y agrupar contaminantes correlacionados. Modelos de regresión logística y binomial negativa evaluaron sus asociaciones con el riesgo y frecuencia de hospitalización. Los resultados mostraron que el estatus económico influyó significativamente en las complicaciones de diabetes, mientras que los factores sociales afectaron enfermedades relacionadas con la atención prenatal y la hipertensión. El grupo PM10–PM2.5–CO aumentó la incidencia de asma, influenza y epilepsia, mientras que NO2–NOx impactó la gravedad de complicaciones de diabetes e influenza.
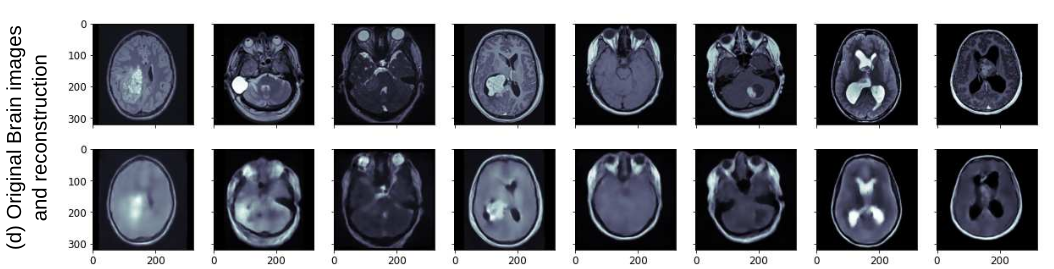
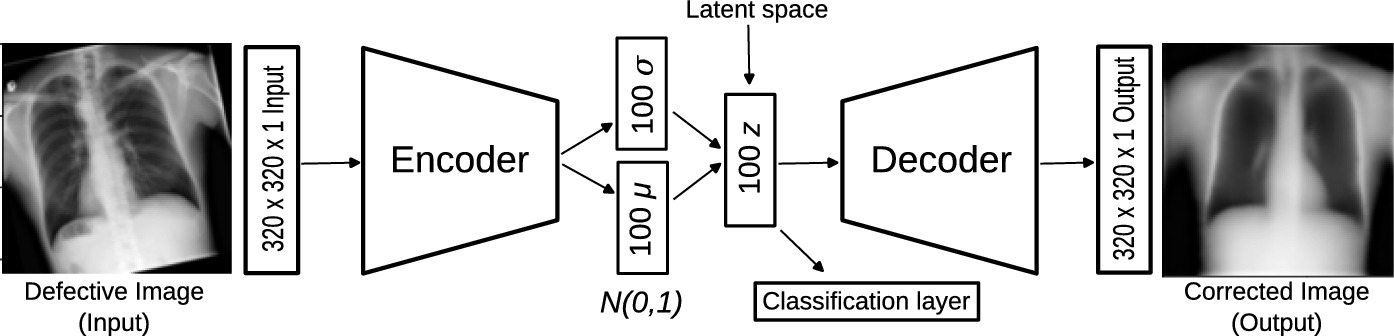
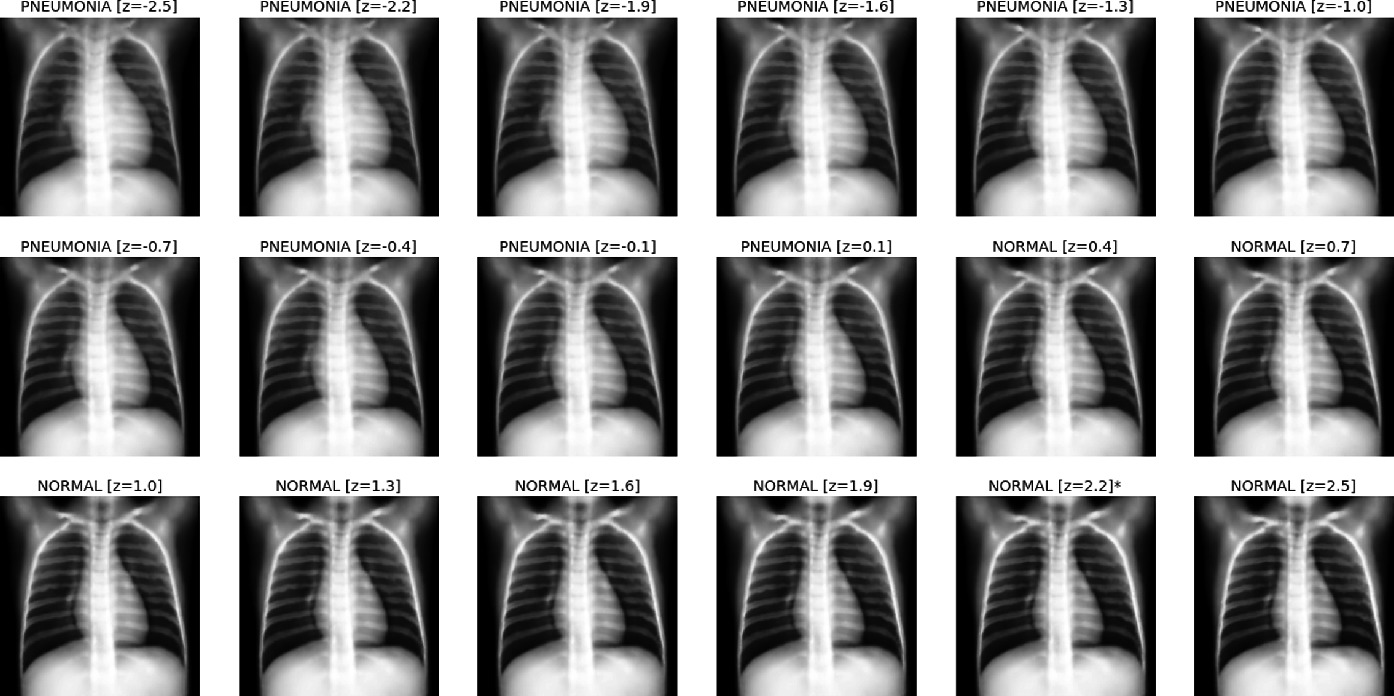
Mejora de la interpretabilidad y control de sesgos en modelos de aprendizaje profundo para análisis de imágenes médicas usando IA generativa
Proceedings of SPIE
La explicabilidad y mitigación de sesgos son aspectos cruciales de los modelos de aprendizaje profundo (DL) para el análisis de imágenes médicas. La IA generativa, particularmente los autoencoders, puede mejorar la explicabilidad analizando el espacio latente para identificar y controlar variables que contribuyen a sesgos. Al manipular el espacio latente, los sesgos pueden mitigarse en la capa de clasificación. Además, el espacio latente puede visualizarse para proporcionar una comprensión más intuitiva del proceso de toma de decisiones del modelo. En nuestro trabajo, demostramos cómo el enfoque propuesto mejora la explicabilidad del proceso de toma de decisiones, superando las capacidades de métodos tradicionales como Grad-Cam. Nuestro enfoque identifica y mitiga sesgos de manera directa, sin necesidad de reentrenamiento del modelo o modificación del conjunto de datos.
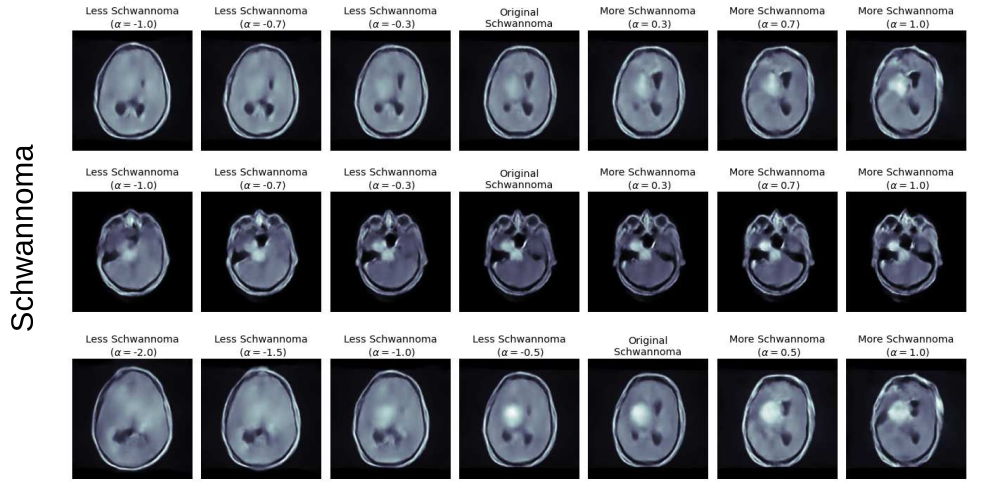
PumaMedNet-CXR: Una Inteligencia Artificial Generativa Explicable para el Análisis y Clasificación de Imágenes de Rayos X de Tórax
Lecture Notes in Computer Science
En este artículo presentamos PumaMedNet-CXR, una IA generativa diseñada para la clasificación de imágenes médicas, con énfasis específico en imágenes de rayos X de tórax (CXR). El modelo corrige eficazmente defectos comunes en imágenes CXR, ofrece mejor explicabilidad, permitiendo una comprensión más profunda de su proceso de toma de decisiones. Al analizar su espacio latente, podemos identificar y mitigar sesgos, asegurando un modelo más confiable y transparente. Notablemente, PumaMedNet-CXR logra un rendimiento comparable al de modelos preentrenados más grandes mediante aprendizaje por transferencia, convirtiéndolo en una herramienta prometedora para el análisis de imágenes médicas.
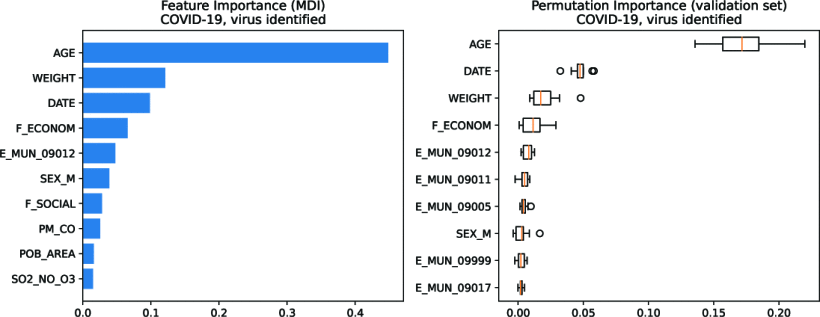
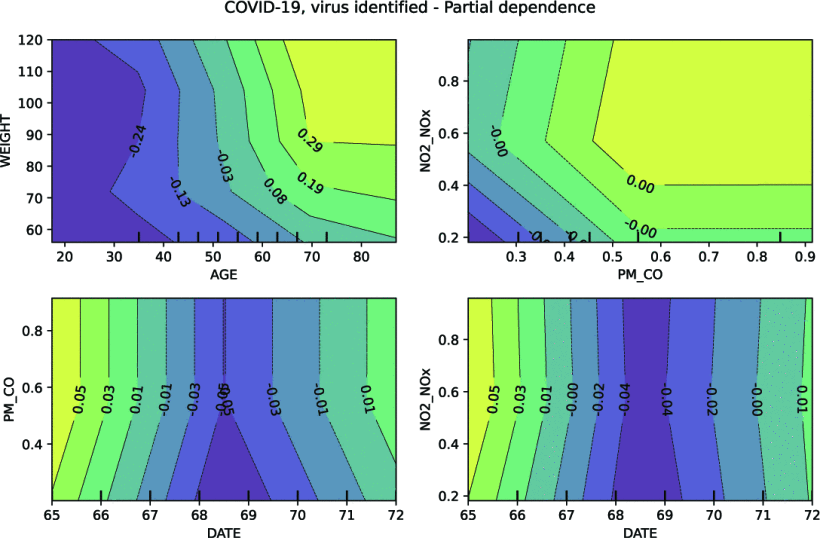
Exploración de efectos no lineales de la contaminación del aire en admisiones hospitalarias por enfermedad usando máquinas de gradient boosting
IEEE
La contaminación del aire se ha vinculado con mortalidad prematura y reducción de la esperanza de vida, con efectos agudos y crónicos en la salud humana. Estos efectos pueden ser difíciles de medir debido a posibles interacciones y relaciones no lineales con otras variables como edad, peso, sexo y estatus socioeconómico. Las relaciones multidimensionales son difíciles de modelar usando métodos estadísticos convencionales. Sin embargo, las técnicas modernas de aprendizaje automático han sido bastante exitosas en este dominio. En este estudio, se utilizan árboles de regresión de gradient boosting para predecir la severidad/mortalidad de las principales causas de hospitalización en la Ciudad de México para 91,964 pacientes durante los años 2015–2020 para medir el impacto de diferentes contaminantes del aire.
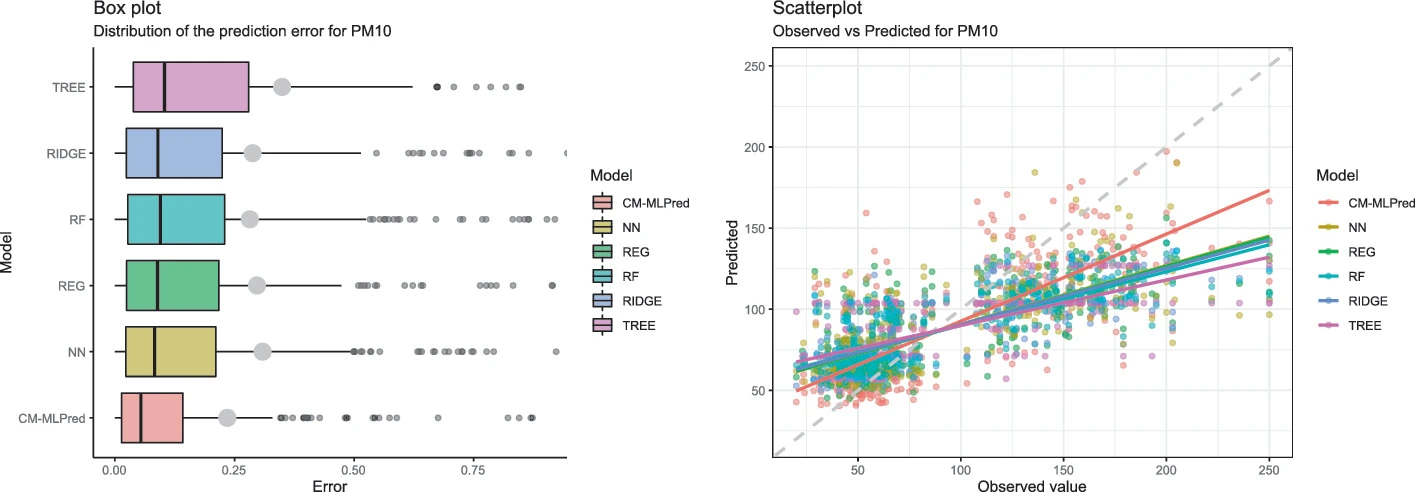
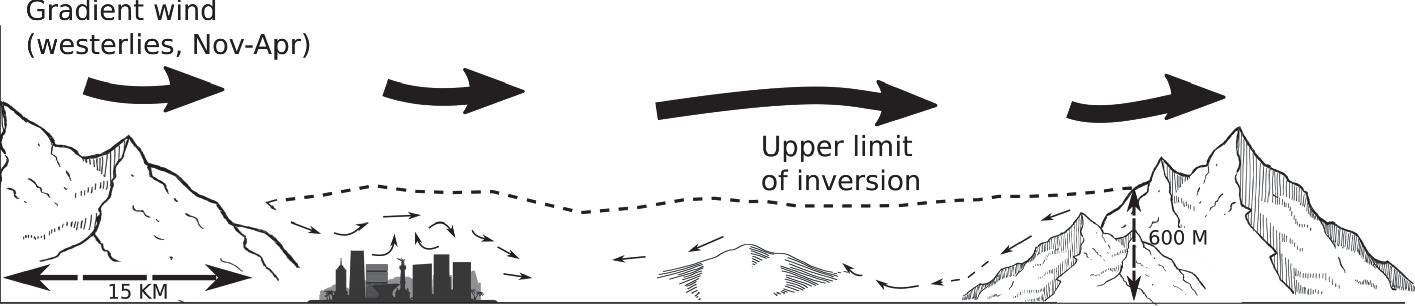
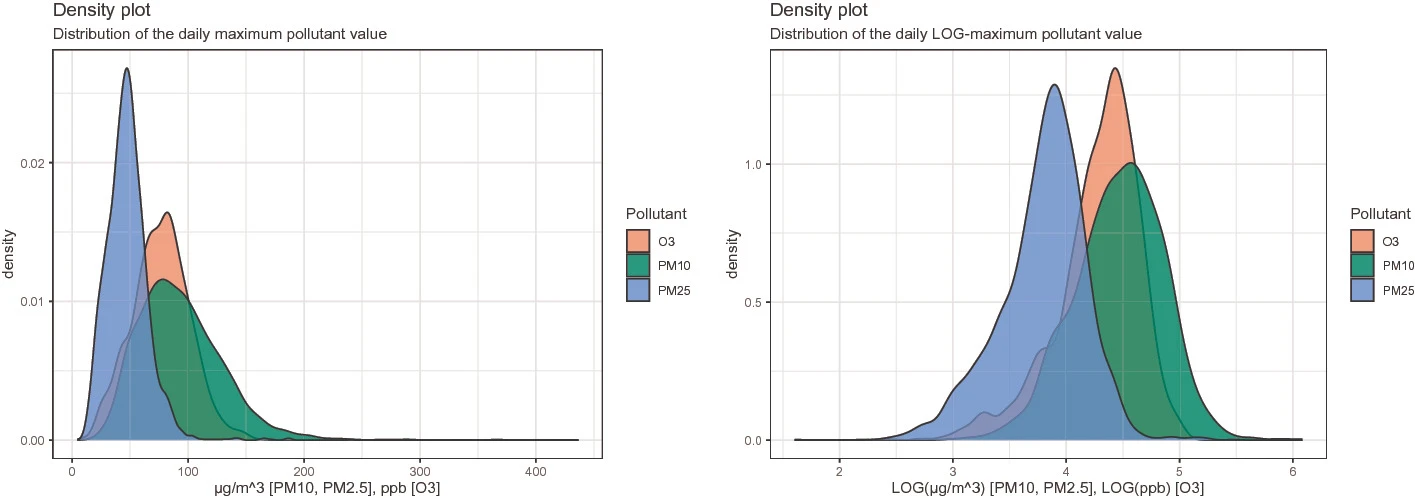
Un Modelo Híbrido para la Predicción de Concentraciones de Contaminantes del Aire, Basado en Técnicas Estadísticas y de Aprendizaje Automático
Lecture Notes in Computer Science
En las grandes ciudades, la salud de los habitantes y las concentraciones de partículas menores a 10 y 2.5 μm así como el ozono están relacionados, haciendo útil su predicción para el gobierno y los ciudadanos. La Ciudad de México cuenta con un sistema de pronóstico de calidad del aire, que presenta un pronóstico por contaminante a nivel horario y por zona geográfica, pero solo es válido para las próximas 24 horas.
Para generar predicciones a un plazo más largo, se necesitan métodos sofisticados, pero técnicas altamente automatizadas como el aprendizaje profundo requieren una gran cantidad de datos, que no están disponibles para este problema. Por lo tanto, se crea un conjunto de variables predictoras para alimentar y probar diferentes métodos de Aprendizaje Automático (AA), y determinar qué características de estos métodos son esenciales para la predicción de diferentes concentraciones de contaminantes.
En este trabajo presentamos un modelo híbrido de predicción utilizando diferentes métodos estadísticos y técnicas de AA, que permiten estimar la concentración de los tres principales contaminantes del aire de la Ciudad de México con dos semanas de anticipación. Se presentan y comparan los resultados de los diferentes modelos, siendo el modelo híbrido el que mejor predice los casos extremos.
Publicaciones
-
"Forecasting an Emerging Market Stock Index: a Comparative Study of Classical and Deep Learning Models". Lorenzo-Landa, G., Minutti-Martinez, C..
International Conference in Software Engineering Research and Innovation, (2025). doi: 10.1109/CONISOFT66928.2025.00049. -
"Multitask Analysis of Spanish Travel Reviews: Sentiment, Destination, and Topic Classification with RoBERTa and LLaMA Ensembles". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
CEUR Workshop Proceedings, (2025). -
"Cyclo-VGAE: Dual-Mechanism Approach to GNN Robustness Against Noisy Labels". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
International Joint Conference on Neural Networks (IJCNN), Roma, Italia, IEEE, pp. 1-8, (2025). doi: 10.1109/IJCNN64981.2025.11227407. -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations: A Multifaceted Analysis". Minutti-Martinez, C., Mata-Rivera, M. F., Arellano-Vazquez, M., Escalante-Ramírez, B., & Olveres, J.
Mathematical and Computational Applications, 30(4), 69. (2025). doi:10.3390/mca30040069 -
"Dynamic Wind Condition Detection in Baja California, Mexico: A Machine Learning Approach for Improved Wind Management". Arellano-Vazquez, M., Zamora-Machado, M., Robles Pérez, M., Minutti-Martinez, C., Jaramillo Salgado, M. O.
IEEE Latin America Transactions., 23(5), 387–396. (2025). -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations in Mexico City: A Multifaceted Analysis". Minutti-Martinez, C., Mata-Rivera, M., Arellano-Vazquez, M., Escalante-Ramírez, B., Olveres, J.
Lecture Notes in Computer Science. Springer, Cham. (2025). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population". Minutti, C.
International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). (2024). -
"A comprehensive methodology for performing Continued Process Verification". Carrillo, R., Minutti, C., Lagunes, P.
IEEE 37th International Symposium on Computer-Based Medical Systems. (2024). -
"Enhancing interpretability and bias control in deep learning models for medical image analysis using generative AI". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
Proceedings of SPIE. (2024). -
"PumaMedNet-CXR: An Explainable Generative Artificial Intelligence for the Analysis and Classification of Chest X-Ray Images". Minutti-Martinez, C., Escalante-Ramírez, B., Olveres-Montiel, J.
Lecture Notes in Computer Science. (2023). -
"Exploring nonlinear effects of air pollution on hospital admissions by disease using gradient boosting machines". Minutti-Martinez, C., Galindo, A., Valdez-Garduño, L. F., Mata-Rivera, M. F.
19th International Conference on Electrical Engineering, Computing Science and Automatic Control. IEEE. (2022). -
"A Hybrid Model for the Prediction of Air Pollutants Concentration, Based on Statistical and Machine Learning Techniques". Minutti-Martinez, C., Arellano-Vázquez, M., Zamora-Machado, M.
Lecture Notes in Computer Science. (2021). -
"A New Inverse Modeling Approach for Hydraulic Conductivity Estimation Based on Gaussian Mixtures". Minutti, C., Illman, W. A., Gomez, S.
Water Resources Research. (2020). -
"Automated characterization and prediction of wind conditions using gaussian mixtures". Arellano-Vázquez, M., Minutti-Martinez, C., Zamora-Machado, M.
Lecture Notes in Computer Science. (2020). -
"An algorithm for hydraulic tomography based on a mixture model". Minutti, C., Illman, W. A., Gomez, S.
Lecture Notes in Computer Science. (2019). -
"A machine-learning approach for noise reduction in parameter estimation inverse problems, applied to characterization of oil reservoirs". Minutti, C., Gomez, S., Ramos, G.
Journal of Physics: Conference Series. 1047 (1), 012010. (2018). -
"A stable computation of log-derivatives from noisy drawdown data". Ramos, G., Carrera, J., Gómez, S., Minutti, C., Camacho, R.
Water Resources Research 53 (9), 7904-7916. (2017). -
"Robust Characterization of Naturally Fractured Carbonate Reservoirs Through Sensitivity Analysis and Noise Propagation Reduction". Minutti, C., Ramos, G., Gomez, S., Camacho, R., Vázquez, M., Castillo, N.
SPE Latin America and Caribbean Heavy and Extra Heavy Oil Conference. (2016). -
"Well-Testing Characterization of Heavy-Oil Naturally Fractured Vuggy Reservoirs". Camacho Velazquez, R., Gomez, S., Vasquez-Cruz, M. A., Fuenleal, N. A., Castillo, T., Ramos, G., Minutti, C., Mesejo, A., Fuentes-Cruz, G.
SPE Heavy and Extra Heavy Oil Conference: Latin America (2014). -
"Avances en la caracterización integral de un yacimiento naturalmente fracturado vugular, el caso Ayatsil-Tekel". Camacho Velázquez, R., Fuenleal Martínez, N., Castillo Rodríguez, T., Gómez Gómez, S., Ramos, G., Minutti Martínez, C., Vásquez Cruz, M., Mesejo, A., Fuentes Cruz, G.
Ingeniería petrolera. 54 (10), 583-601 (2014).
Conferencias Internacionales
-
"Cyclo-VGAE: Dual-Mechanism Approach to GNN Robustness Against Noisy Labels".
International Joint Conference on Neural Networks 2025. Roma, Italia. (2025). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population".
2024 21st International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Cinvestav, Ciudad de México. (2024). -
"Air Pollution, Socioeconomic Status, and Avoidable Hospitalizations in Mexico City: A Multifaceted Analysis".
6th Workshop on New Trends in Computational Intelligence and Applications. INAOE, Puebla, México. (2024). -
"Unraveling the Complex Interplay Between Socioeconomic Status, Air Pollution, and Heart Disease Hospitalizations in an Urban Population".
21st International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Ciudad de México, México. (2024). -
"Enhancing interpretability and bias control in deep learning models for medical image analysis using generative AI".
SPIE Photonics Europe 2024. Estrasburgo, Francia. 7-11 de abril. (2024). -
"PumaMedNet-CXR: An Explainable Denoising Autoencoder for the Analysis and Classification of Chest X-Ray Images".
22ª Conferencia Internacional Mexicana de Inteligencia Artificial, 13-18 de noviembre, IIMAS-UNAM (UAEY) - UADY, Mérida, Yucatán, México. (2023). -
"Exploring nonlinear effects of air pollution on hospital admissions by disease using gradient boosting machines".
19th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Ciudad de México, México. (2022). -
"Automated Prediction of Air Pollutant Concentrations in Mexico City, Using Artificial Intelligence Methods".
20th Mexican International Conference on Artificial Intelligence. 25-30 de octubre, Ciudad de México, México. (2021). -
"An algorithm to perform hydraulic tomography based on a mixture model".
International Conference on Computational Science. 12-14 de junio, Faro, Algarve, Portugal. (2019). -
"An approach for noise reduction in inverse problems, applied to well-test data".
9th International Conference on Inverse Problems in Engineering. 23-26 de mayo, Universidad de Waterloo, ON, Canadá. (2017). -
"A Methodology for the Characterization of Naturally Fractured-Vuggy Carbonate Reservoirs Using Statistical Methods".
Eighth International Conference "Inverse Problems: Modeling and Simulation". 23-28 de mayo, Ölüdeniz, Fethiye, Turquía. (2016).
Premios y Distinciones
- Top 10 en el programa “Acelerando México con Inteligencia Artificial” de Intel, edición 2025. (2025).
- 2º Lugar en la competencia de Procesamiento de Lenguaje Natural (PLN) "Researching Sentiment Evaluation in Text for Mexican Magical Towns" (Rest-Mex 2025) en el Iberian Languages Evaluation Forum (IberLEF) 2025.
- 1er Lugar en la competencia "Learning with Noisy Graph Labels" en la International Joint Conference on Neural Networks 2025 de la International Neural Network Society (INNS).
- 3er Lugar en la categoría de investigación del premio AFIRME-FUNAM, que promueve y reconoce la investigación científica en las áreas de Ciencias Físico-Matemáticas e Ingeniería, a través de la Universidad Nacional Autónoma de México y el Grupo Financiero AFIRME. (2024).
- Becario del programa INFOTEC-HUAWEI AI 1000 Talent Development. De 1000 participantes, el programa AI 1000 premia a los 100 mejores resultados de certificación Huawei HCIA-AI con un programa de capacitación de 2 semanas en IA en las instalaciones de Huawei en Hangzhou, China. (2024).
- 1er Lugar Premio al Mejor Artículo en la 22ª Conferencia Internacional Mexicana de Inteligencia Artificial por la Sociedad Mexicana de Inteligencia Artificial. (2023).
- Miembro del Sistema Nacional de Investigadores (SNI). Área Interdisciplinaria. (2023).
- Clasificado en el top 3% (Medalla de Plata) de la competencia de Ciencia de Datos / IA "Google Smartphone Decimeter Challenge", con 810 equipos y 985 competidores de todo el mundo. (2021).
- Becario del programa Emerging Leaders in the Americas para oportunidades de intercambio a corto plazo para estudio o investigación, en Canadá. (2017).
- Segundo lugar por la mejor tesis de maestría en estadística. Premio nacional de la Asociación Mexicana de Estadística (AME), Premio Francisco Aranda-Ordaz. (2016).